The Multi-LLM Strategy
Why Orchestrating Beats Chasing Benchmarks


Most users are still looking for the single best AI model. They are asking the wrong question.
The right question is: which models work best together? Because no single large language model handles everything well. Between late 2024 and early 2025, every major AI lab released flagship models within weeks, creating a wave of specialized innovation. Gemini 3 Pro arrived with a massive context window for deep research (1). Claude Opus 4.5 achieved new accuracy in financial modeling (2). Grok 4.1 mastered real-time market sentiment (3). GPT-5.1 optimized for daily workflow efficiency (4).
The practical result is a market defined by high-performance specialization. Your competitive edge will not come from picking a winner, but from building a team. This reality demands a new, model-agnostic approach: orchestrating a council of specialized AI models. The new game is building councils (5).
The Tyranny of the Leaderboards
Every week, a new model claims the top spot on a different leaderboard. Yet these benchmarks measure narrow technical capabilities, not how a model performs in the messy reality of business over months. This disconnect is evidenced by the persistent “insight gap” identified in evaluations of AI “Deep Research” tools. While these systems excel at rapid, polished synthesis, they consistently lack critical judgment and produce surface-level analysis, confusing linguistic fluency for genuine understanding (13). Testing models on real, long-term projects reveals the truth: it is not about winners. It is about fit for purpose. The best approach is for everyone to test them personally on real projects spanning at least several months.
How to Think About Your AI Team
Think of leading models as specialized hires for your digital team. You would not ask your CFO to do market sentiment analysis, nor your head of R&D to manage daily communications. The same principle applies here. The key is to match the model’s innate strength to the specific cognitive task at hand.

Table 1: The LLM Council I used during two Go‑to‑Market projects in 2025.
The advantage is operational: you get the right mind for the job at the right cost (6). This specialist approach is a direct response to the documented strengths and limitations of each model. Independent evaluations of Deep Research capabilities, for instance, consistently find that Claude excels in balanced, nuanced synthesis but can be conservatively scoped, while Grok delivers real-time speed but with variable source quality. This is precisely why you would task them with different roles in a council (13; See Table 1).
The Three Patterns of a Council: A Practical Framework
You can implement this strategy through three distinct workflow patterns. To illustrate how each works from start to finish, let us follow a complete scenario: launching an AI-powered recruiting tool that uses graph-based inference to identify rare talent combinations through skill adjacency rather than keyword matching, a product entering a nascent market with no established category.
Pattern 1: The Assembly Line (For Multi-Stage Workflows)
When to Use It: You have a linear project with distinct stages that benefit from different specializations, such as research, analysis, and synthesis (7) (Figure 1).
On the Question of Order: A natural question arises: in which order should the models run? There is no universal sequence, but a guiding principle: progress from foundation to refinement. The job should get better as it moves from one specialist to the next. Start with the model best suited to gather or create the foundational material (for example, Gemini for broad research, Claude for a first draft). Then pass that output to the model best equipped to critique, enhance, or transform it (for example, Grok for real-world validation, DeepSeek for logical verification). The final stage should be handled by the model whose core strength is synthesis, polish, and clarity (for example, Claude for structured narrative). The order in the example below is not a rule; it is a strategic choice designed to amplify quality at each step.
Stage 1: Deep Research and Synthesis (Gemini 3 Pro): “We are defining a new market category for an AI recruiting tool that finds candidates based on skill adjacency and graph-based inference, not keywords. Research and synthesize: 1) studies on the failure rate of Boolean search in tech hiring over the past 18 months, 2) industry reports on recruiter pain points and time allocation, 3) existing solutions (LinkedIn Recruiter, ATS platforms, AI sourcing tools) and their documented gaps. Use your 1M context window to process multiple sources simultaneously. Output a summary of the uncontested market opportunity with specific data points.”
Stage 2: Live Market Validation (Grok 4.1): “Using this market thesis [paste Gemini output], search the last 60 days of conversations on X, LinkedIn, and industry HR forums. Find: 1) direct quotes from recruiters expressing frustration with current search tools, specifically mentioning Boolean complexity or false positive rates, 2) sentiment on AI in recruiting (enthusiasm vs. skepticism about replacement vs. augmentation), 3) any mentions of startups or features related to skill graphs, network-based hiring, or adjacency matching. Exclude unverified social media commentary; focus on professional discussions and verified accounts.”
Stage 3: Strategic Positioning and Go-To-Market Outline (Claude Opus 4.5): “Synthesize the deep research [Gemini output] and live market signals [Grok output] to create our launch foundation. First, write a definitive positioning statement using Geoffrey Moore’s framework: For [target customer], who [specific problem], our product is [category definition], that [key benefit], unlike [alternatives]. Make it concrete and avoid generic productivity claims. Second, outline the core elements of a 90-day go-to-market plan targeting tech recruiters at mid-sized companies (50 to 500 employees). Focus on the psychological insight that workers want AI to automate tasks they find tedious, not tasks they find meaningful.”
The Business Outcome: In a few hours, you move from a novel idea to a research-backed, market-validated strategy with clear positioning and launch priorities, leveraging each model’s strength at the optimal stage.
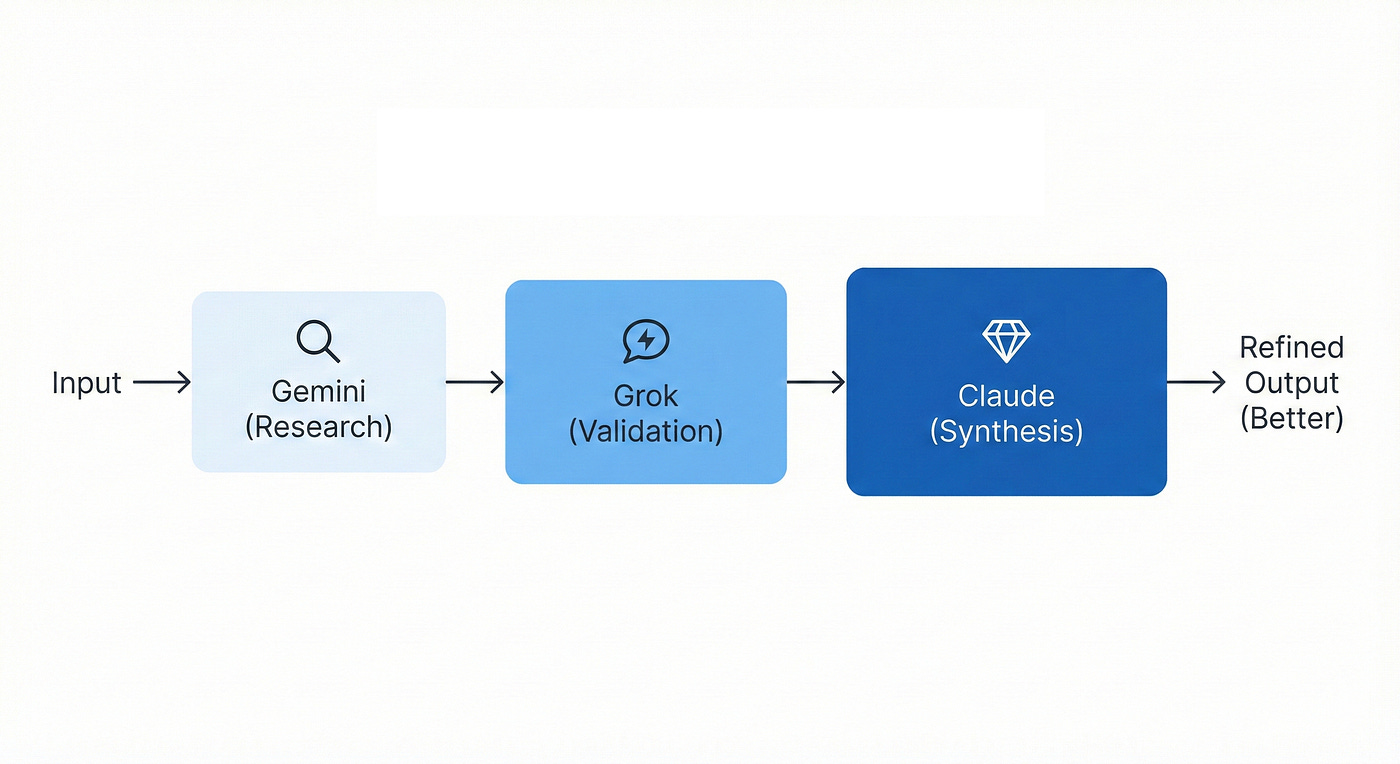
Figure 1: The Assembly Line Pattern. This linear, multi-stage workflow leverages the specialized strengths of different models in sequence. By progressing from Gemini’s deep research and foundation-building to Grok’s real-world validation, and finally to Claude’s structured synthesis, the project gains compounding quality and refinement at every handoff.
Pattern 2: The Debate Club (For Validation and Risk Mitigation)
When to Use It: You need to pressure-test a critical assumption, strategic decision, or high-stakes output before committing resources. This approach automates the triangulation of truth from different models (8) (Figure 2).
Pose the Critical Questions in Parallel:
To the Logician (DeepSeek V3.2): “Critically evaluate this claim: Recruiters in tech companies waste substantial time on manual Boolean searches that yield mostly false positives. Find the strongest supporting data from industry reports or academic studies. Identify the weakest, least substantiated part of this assertion. Show your reasoning chain and flag any claims you cannot verify with concrete evidence.”
To the Contrarian (Grok 4.1): “Act as a skeptical CFO evaluating this business case. Challenge this pricing model: 500 dollars per seat per month for an AI recruiting tool that uses graph-based skill matching. What are the top two objections you would raise? Based on current market sentiment and competitor pricing (LinkedIn Recruiter costs 8K to 10K annually per seat), what price point would feel like an obvious yes versus a maybe for a recruiting director at a 200-person tech company?”
To the Strategist (Claude Opus 4.5): “Analyze this product positioning as a skill decoder agent that eliminates tedious search work with proposed pricing at 500 dollars per seat per month. Does the pricing support the positioning as a premium, category-defining tool? Or does it undermine credibility? Suggest one specific adjustment to either the positioning or the pricing to improve overall market fit and buyer psychology.”
The Business Outcome: You expose logical flaws, pricing sensitivities, and strategic misalignments early, before they become expensive mistakes. This pattern is invaluable for risk assessment, compliance checking, and strategic analysis where accuracy is paramount. The debate format forces each model to take a different perspective, preventing the sycophancy trap where all models agree too readily (8).
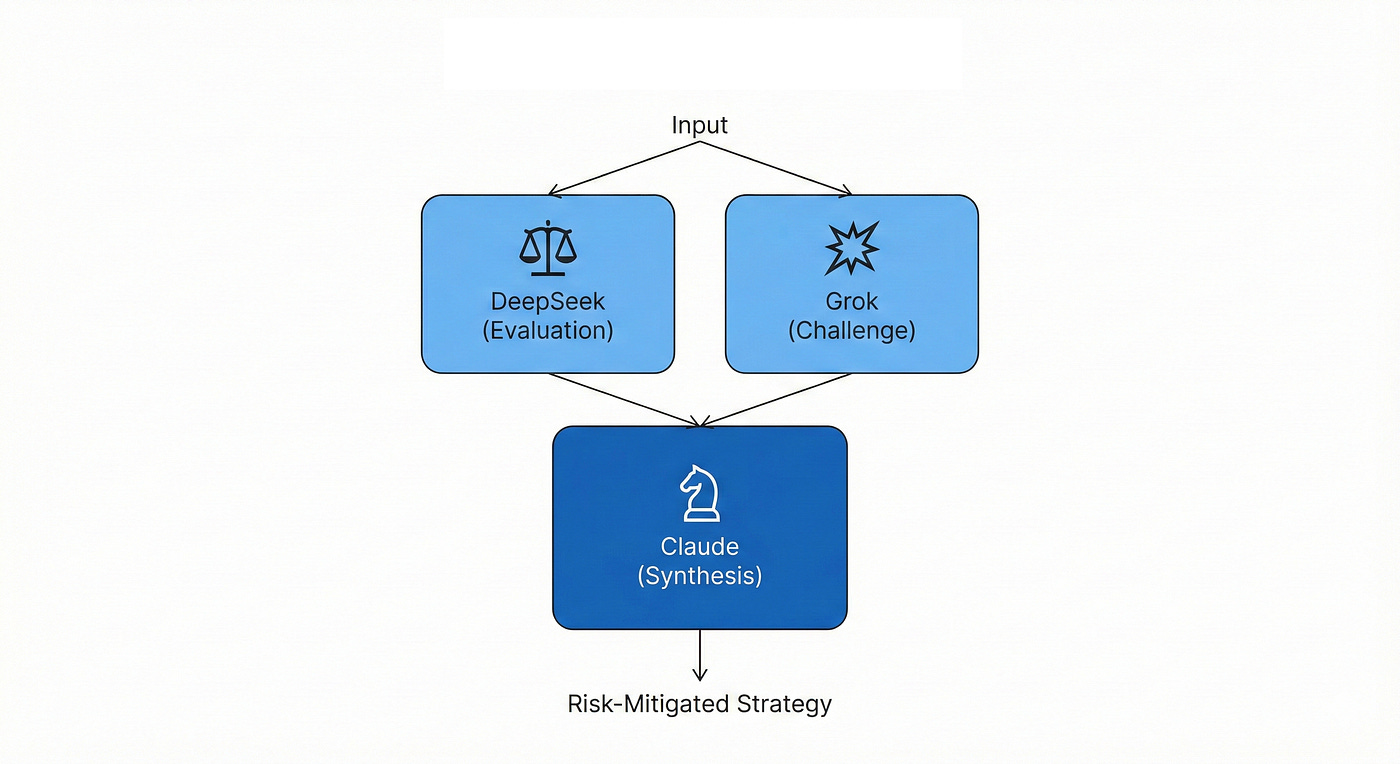
Figure 2: The Debate Club Pattern. Designed for high-stakes risk mitigation, this architecture uses parallel processing to automate the triangulation of truth. By forcing a “Logician” like DeepSeek and a “Contrarian” like Grok to challenge the same core assumptions, the system exposes logical flaws and biases before a final, pressure-tested strategy is synthesized.
Pattern 3: The Triage System (For Cost-Optimized Execution)
When to Use It: You have a high volume of tasks with variable complexity and need to optimize for both cost and performance. This hierarchical routing prevents using premium compute for simple tasks while ensuring complex problems get appropriate depth (6).
Route Simple, Tactical Tasks: GPT-5.1 Instant (No Reasoning Mode):
“Generate 10 subject line options for a launch email to recruiting directors at tech companies. The tool automates Boolean search work. Keep subject lines under 60 characters, professional tone.”
“List the top 5 US states by concentration of IT consulting firms with 20 to 500 employees. Include approximate firm counts if available from public data.”
Route Analytical and Drafting Tasks: Claude Opus 4.5:
“Draft the Problem section of our sales one-pager for an AI recruiting tool. Address these pain points from our research: 1) recruiters spend excessive time on Boolean searches (cite the 222 applications per job average), 2) high false positive rates exhaust talent teams, 3) rare skill combinations go undetected by keyword matching. Make it relatable to a recruiting director’s daily experience. Keep it under 300 words. Avoid jargon like graph-based inference and focus on the outcome, not the technology.”
“Create a detailed FAQ document addressing common concerns about AI bias in recruiting tools. Use the regulatory research on EU AI Act high-risk classification, NYC Local Law 144 bias audit requirements, and EEOC guidance. Explain our mitigation approach: human-in-the-loop for all final decisions, audit trails, and bias monitoring. Professional but accessible tone for HR buyers.”
Route Complex, Synthetic Tasks: Gemini 3 Pro (Deep Think Mode):
“We are entering the US market first, with plans for EU expansion in 12 months. Our product is an AI recruiting tool classified as high-risk under the EU AI Act. Compare the compliance requirements of NYC Local Law 144 (bias audits, notification, public reporting) versus the EU AI Act (systemic risk obligations, incident reporting within 2 to 15 days depending on severity, conformity assessments). Based on this analysis, draft a phased compliance roadmap for our engineering and legal teams. Address: 1) what controls must be operational before US launch, 2) what preparation enables faster EU entry, 3) what documentation and audit infrastructure is required. Use Deep Think mode for multi-step legal and strategic reasoning across jurisdictions.”
The Business Outcome: You prevent overthinking simple tasks and underthinking complex ones. This hierarchical routing can reduce AI costs by 50 to 60 percent while maintaining appropriate quality at each level (6). Simple tactical work gets instant responses at 1.25 dollars per million tokens (4). Complex regulatory analysis gets premium compute. The middle tier handles most day-to-day drafting and analytical work efficiently.
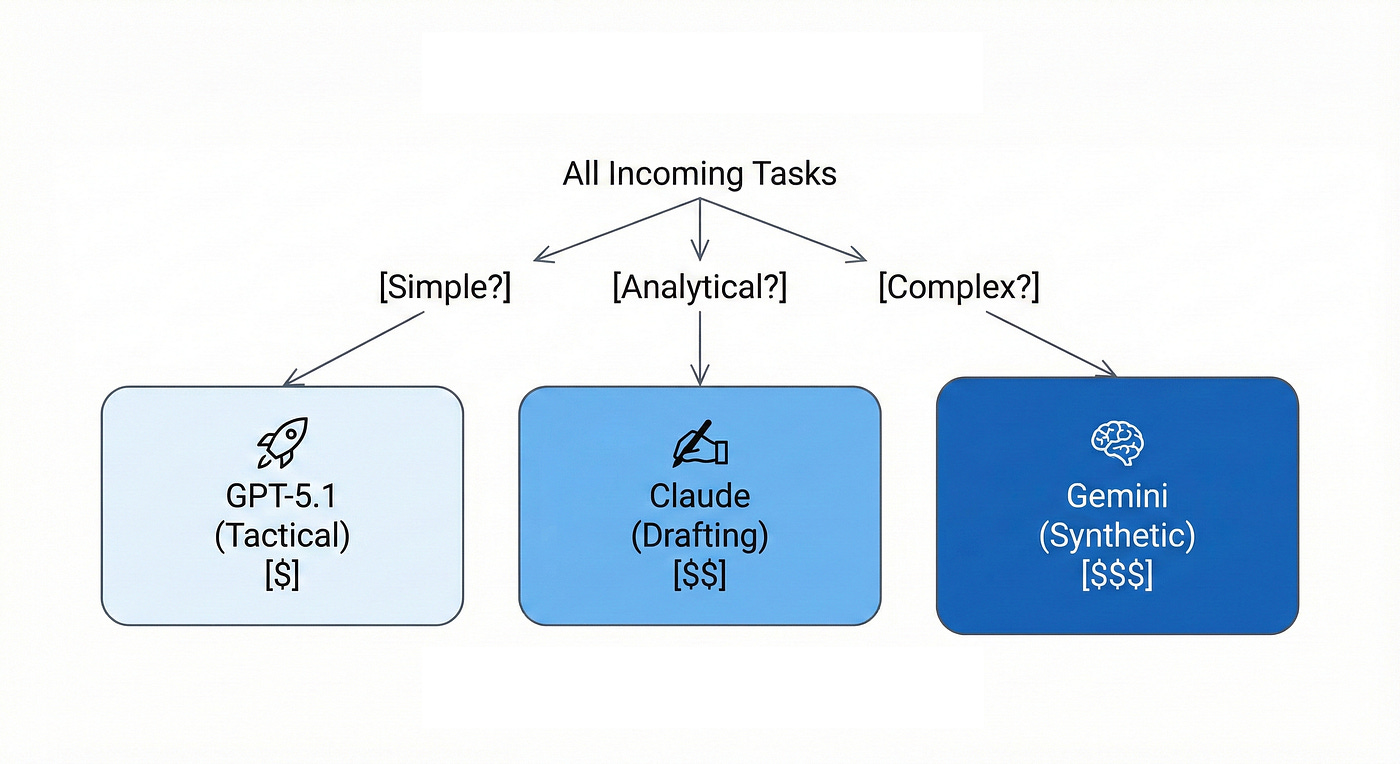
Figure 3: The Triage System Pattern. A hierarchical routing framework built for cost and performance optimization. This pattern prevents “compute waste” by automatically directing simple tactical tasks to efficient models like GPT-5.1, while reserving premium, high-reasoning compute for complex analytical drafting and multi-step strategic synthesis.
Critical Lessons for Implementation
Treating your council as an oracle leads to failure. They are brilliant, specialist interns that require management.
1. Mandate Dissent: Models are trained to be helpful, which can create an echo chamber. You must explicitly prompt for conflict. Start instructions with: Challenge this assumption, or Act as a skeptical board member. The very design of councils forces models to debate and critique each other’s work, acting as a filter to reduce confident errors before a final answer is given (8). This forced debate is the antidote to the illusion of reasoning where models produce coherent but shallow or inaccurate causal links, a well-documented failure mode of single-model research (13)(14).
2. Break the Consensus Trap: If all models agree too readily, their outputs become generic. Introduce an outsider. Feed Grok real-time data to contradict stale analysis, or use DeepSeek’s unique reinforcement learning logic to challenge groupthink emerging from supervised fine-tuning (9).
3. Maintain a Shared Context: A critical caveat of councils is that LLMs do not know what the others know. They operate in isolation for each prompt. To keep them in sync during sequential processes, you must manually share the growing context. A simple and effective method is to copy the key outputs from each step into a single master document. This document then becomes the shared source of truth that you paste into the prompt for the next model in the chain, ensuring continuity and coherence (5).
The Conductor’s Mindset: Your Role in the Council
Implementing these patterns is not about finding a single best workflow. In practice, you will move fluidly between the Assembly Line, Debate Club, and Triage System, often within the same project. The choice is tactical, not doctrinal.
Three principles separate effective orchestration from mere tool collection:
1. You Are the Decider, Not the Council. The council raises quality and speed, but you define what done means. You evaluate the output, synthesize the final judgment, and own the outcome. The goal is to elevate your thinking, not outsource it. This enshrines the essential human role identified in assessments of AI research tools: they are powerful information engines, but insight engines they are not (6; 13). The LLMs provide perspective and draft material; you provide the intent, ethics, and final meaning.
2. Embrace Iteration, Not Magic. The examples shown are simplified for clarity. Real work is iterative. You will refine prompts, send outputs back for revision, and sometimes cycle through multiple debate rounds. The council is not a one-prompt solution; it is a dynamic workspace that accelerates your iterative process.
3. Cultivate LLM Neutrality. The landscape changes quarterly. Today’s benchmark leader may be obsolete in six months. The true strategic advantage lies not in betting on a single vendor, but in building a resilient, LLM-neutral approach. Your templates and workflows should be adaptable, allowing you to swap in new, better models as they emerge without rebuilding your entire process. The goal is to use whatever the landscape offers, not to find a permanent best model.
Building Your First Council: A Practical Start
You do not need a team of developers to begin. Start with accessible tools and clear experiments (5).
1. Audit Your Week: Identify 3 to 5 time-consuming tasks: sifting through market reports, drafting client communications, analyzing competitive positioning, synthesizing research across multiple sources.
2. Match a Model to One Task: Next time you do this work, try a specialist. Use Gemini’s 1M context window for processing lengthy market reports (1). Use Claude to draft the strategic communication (2). Use Grok to check real-time sentiment (3). Compare the output quality and time saved to your usual method.
3. Create a Simple Template: In a document, build a starter template: For [Task Type], first consult [Model A] for [Strength], then validate with [Model B] for [Counter Perspective]. Synthesize key points without meta-commentary about the process.
4. Track and Iterate: Note what works and what fails. Models and prices change quarterly. Claude’s pricing dropped 70 percent between Opus 4 and Opus 4.5 (2). Your council is a dynamic team, not a static software purchase. Instrument cost per task, quality scores, and time savings. Adjust routing quarterly based on evidence.
The Strategic Outcome
The future is not one AI overlord, but a well-managed portfolio of specialized intelligence. Your competitors might be fixated on which model is best this week. You will have moved past that, operating with a scalable, resilient cognitive team that amplifies your strategic judgment. This architectural approach aligns with the emerging best practice of being multi-model by default, routing tasks to the optimal tool (7).
Over a third of enterprises now report using five or more models in parallel (10)(12), treating models as interchangeable parts rather than vendor dependencies. The decisive shift is architectural, not competitive. Sophisticated buyers assume multi-model deployments by default (10).
Value no longer comes from accessing a single, powerful voice. It comes from your ability to orchestrate the right voices at the right time. Your new role is not AI prompt engineer, but AI conductor. You are the human decider who orchestrates specialized tools, iterates towards excellence, and remains strategically neutral in a volatile landscape.
References
1. Comet. Gemini 2.5 series: specs and benchmark highlights. December 2025.
2. Anthropic. Claude 4.5 Sonnet: model and release materials. September 2025.
3. xAI. Grok 3 Beta: The Age of Reasoning Agents. February 2025.
4. OpenAI. GPT-5: system card and launch materials. August 2025.
5. Analytics Vidhya. LLM Council: Andrej Karpathy’s AI for Reliable Answers. December 2025.
6. Lambert, N. Deep Research, Information vs. Insight, and the Nature of Science. Interconnects. February 2025.
7. The Engineering Manager. Councils of agents: group thinking with LLMs. October 2025.
8. Level Up GitConnected. The LLM Council: When AI Models Debate Each Other to Give You Better Answers. November 2025.
9. VentureBeat. DeepSeek V3.2 architecture, licensing, and cost dynamics. December 2025.
10. Andreessen Horowitz. The Real State of AI: 2025 Enterprise CIO Survey. December 2025.
11. TechCrunch. Anthropic overtakes OpenAI in enterprise market share, says Menlo Ventures. December 2025.
12. OpenRouter and Andreessen Horowitz. The 2025 State of AI Report: An Empirical 100 Trillion Token Study. December 2025.
13. Lâasri, H. Deep Research in AI: The Insight Gap. A Critical Assessment of Automated Analysis in Large Language Models. December 2025.
14. Apple Machine Learning Research. The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models. 2025.
About the Author
Hassan Lâasri advises startups, growth companies, and enterprises on integrating data, AI, and technology into core strategies and operations. With decades of experience leading complex projects, he delivers impactful strategies and transformative AI solutions across retail, tech, finance, and media sectors. Based in Paris, he advises clients globally.
He holds a PhD in blackboard systems (AI) from INRIA, France, and completed a postdoctoral fellowship in multi-agent systems (distributed AI) at the University of Massachusetts Amherst.
Connect: linkedin.com/in/hassanlaasri
This article is also available on Medium.
When employing a multi-LLM strategy, avoid having one model craft or refine prompts for the others. While a model may attempt the task, it cannot account for the internal workings of its counterparts.
A more reliable method, based on my experience with megaprompts, is this:
1. First, establish and refine the core specifications. Circulate them to achieve a robust, consensus foundation.
2. Then, let each model generate its response independently from that single source.